【PaperReading】NeuRex
NeuRex: A Case for Neural Rendering Acceleration
Seoul National University 首尔大学
Modern Neural Rendering
目前神经渲染中的典型模型
- NeRF: Neural Radiance Field
- NSDF: Neural Signed Distance Field
- GIA: Gigapixel Image Approximation
- NVR: Neural Volume Rendering
Modern Neural Rendering Pipeline

Input Encoding: Multi-Resolution Hash Encoding
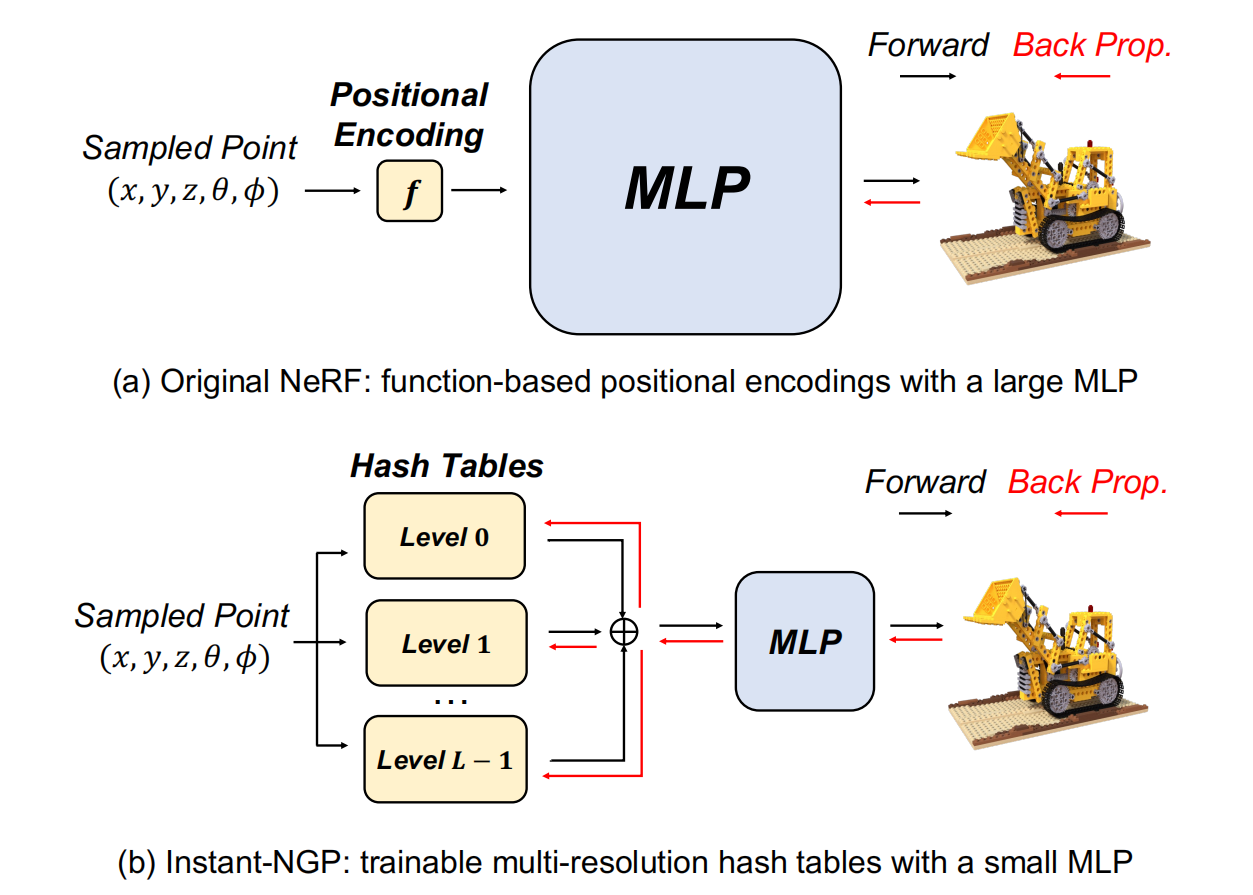
Computations Of Multi-Resolution Hash Encoding
Default Parameters Of NGP
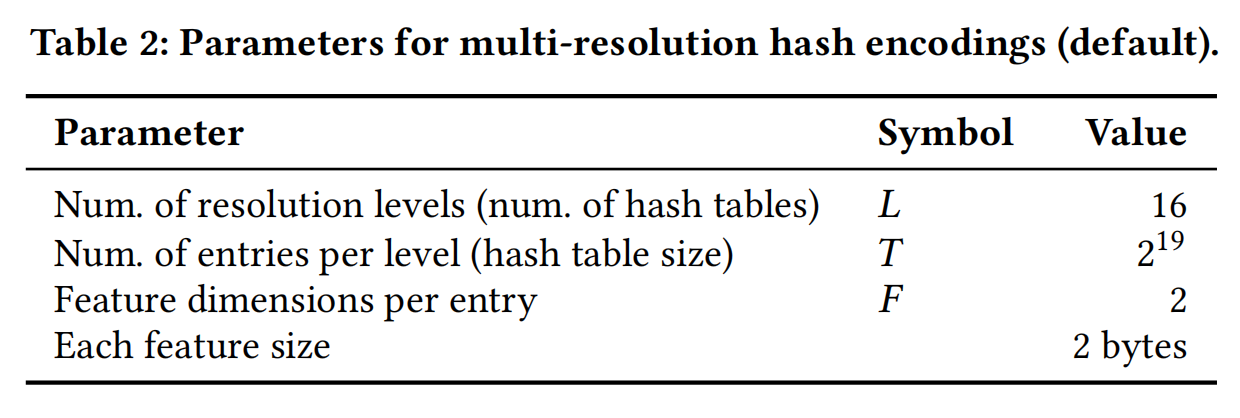

- $N_\text{point}$ 个 Input Position
- 通过十六个 Hash Table,每个 Table 取 $F=2$ 个 Feature
- 形成 $N_\text{Point}\times 32$ 大小的 Input Feature Matrix
- 以上 Input Feature Matrix 输入 The Density MLP
- 得到 $N_\text{Point}\times 16$ 大小的 Position Feature
- Direction 被 (SH)Encoding 成 $N_\text{Point}\times 16$ 大小的 Direction Feature
- 以上两个 Feature 被拼成 $N_\text{Point}\times 32$ 大小的 Feature 输入 Color MLP中,输出最终预测的颜色。
Motivation: Latency Breakdown

瓶颈:
- ENC:Hash Encoding
- MLP:Feature Computation
Observations
Performance portability of multi-resolution hash encodings
- 尽管哈希表查找的时间复杂度是 $𝑂(1)$,但这不是一种适合硬件的操作。
- 理想的 Hash Function 输出 随机的 Index,没有 Locality
- 会频繁发生 Off-Chip Memory Access
- 每次的 Access 仅使用 4 Byte 数据(For $F=2$),带宽大量浪费
- 理想的 Hash Function 输出 随机的 Index,没有 Locality
一种目前的解决方案
- 按层次加载 Hash Table
- 每次先遍历所有的点,把这层 Hash Table 对应的 Feature 取出来
- 再 Load 下一层 Hash Table
- 仍然很慢
Serialized execution of rendering pipeline
- 目前花费渲染时间最多的两个主要操作是哈希编码(ENC)和特征计算(MLP)
- 这两个主要操作会串行执行
- ENC对存储带宽要求较高,而MLP需要更多的计算资源
- 在完成所有 Hash Table 查找之前,MLP 无法进行
Difference in access characteristics across different levels of hash tables.
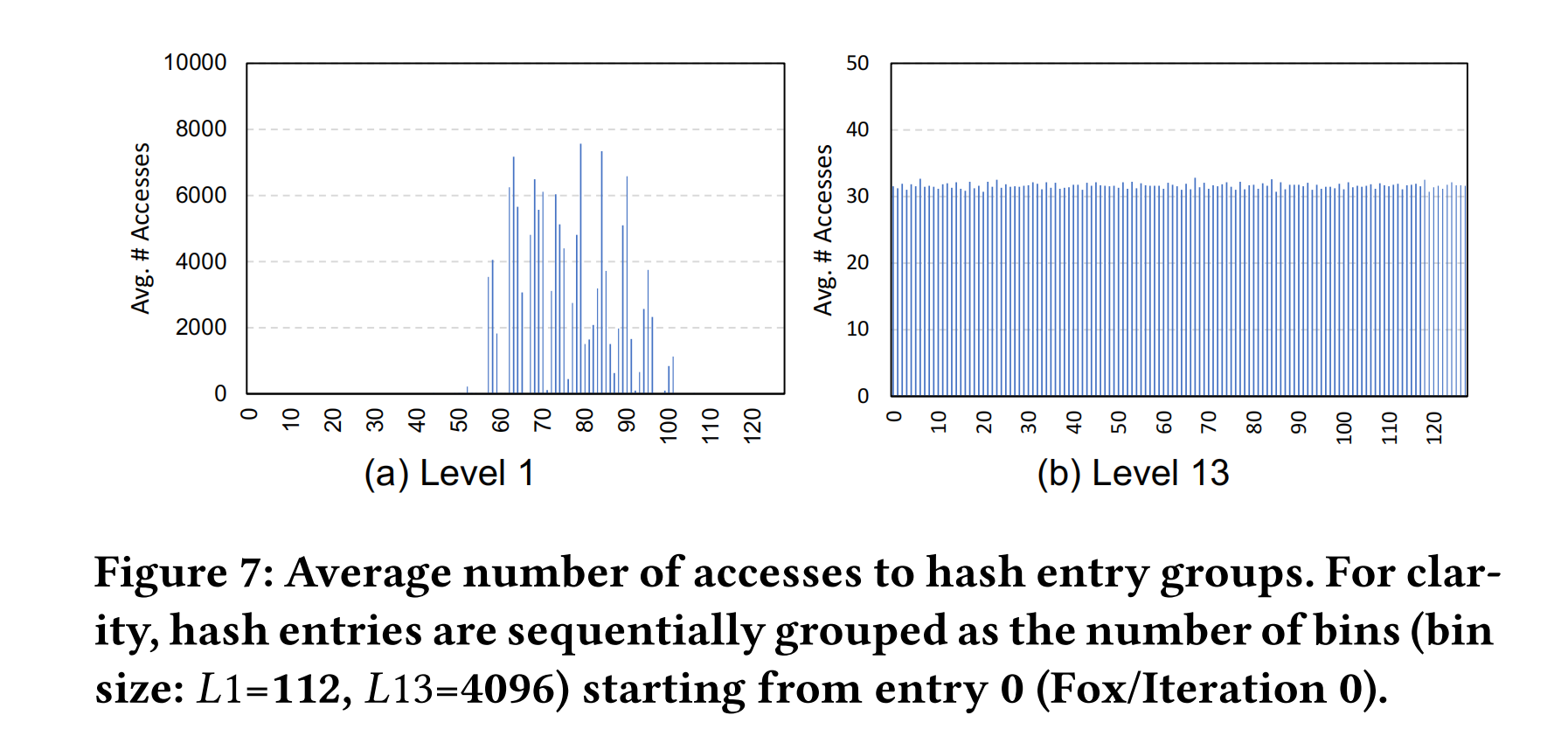
- 对于没有哈希冲突的分辨率级别(例如, $𝐿=1$ )
- 哈希表条目仅被分配给体素网格的单个顶点
- 一个体素中有大量的采样位置共享相同的顶点
- 访问在几个条目上有一定的局部化,并且每个条目的访问次数很高
- 对于更细的分辨率级别(例如,$𝐿=13$ )
- 访问更均匀(且随机)地分布在哈希表条目之间
- 每个条目的访问次数非常低。
NeuRex: Neural Graphics Engine
Execution FLow

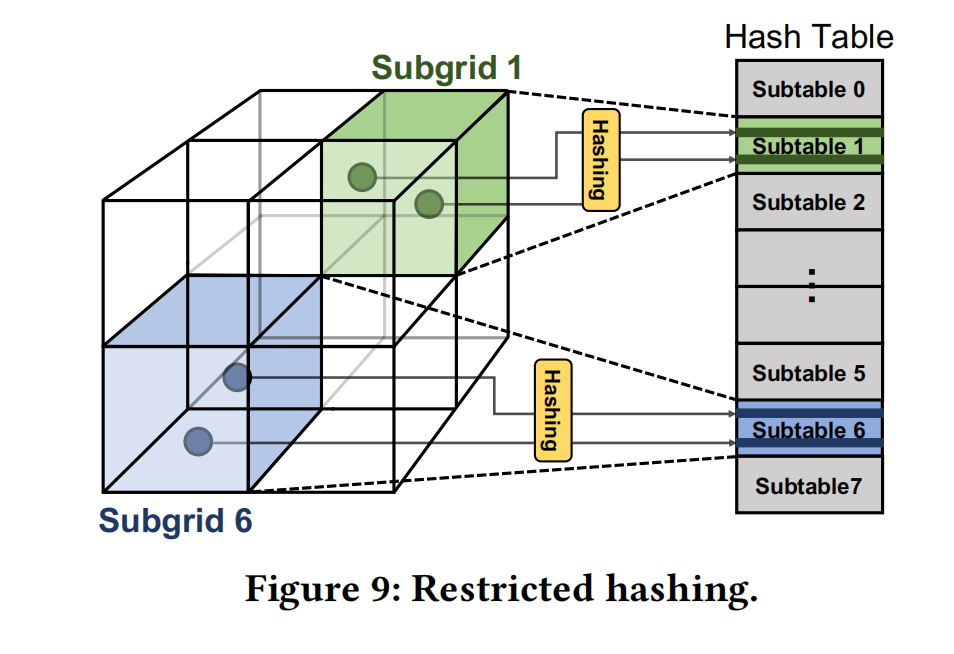
Restricted Hashing
- 将 Input Coordinate Grid 划分为若干 Subgrids
- 每个 Subgrid 都拥有每个层级的大型哈希表的一部分
- 在处理另一个子网格之前,先完成所有分辨率下的一个子网格的处理。
Architecture Overview

两个主要模块:
Encoding Engine(EE)
- 主要负责 Hash Table Lookups 和 Interpola
Tensor Compute Engine(TCE)
- 脉动阵列实现 MLP 计算
Experiment & Evaluation

NeuRex Performance
- NeuRex-Server: $2.88\times$
- NeuRex-Edge: $9.17\times$
- On-Chip Cache 比较小的时候,对 Hash Table 的 Random Access 成为性能瓶颈
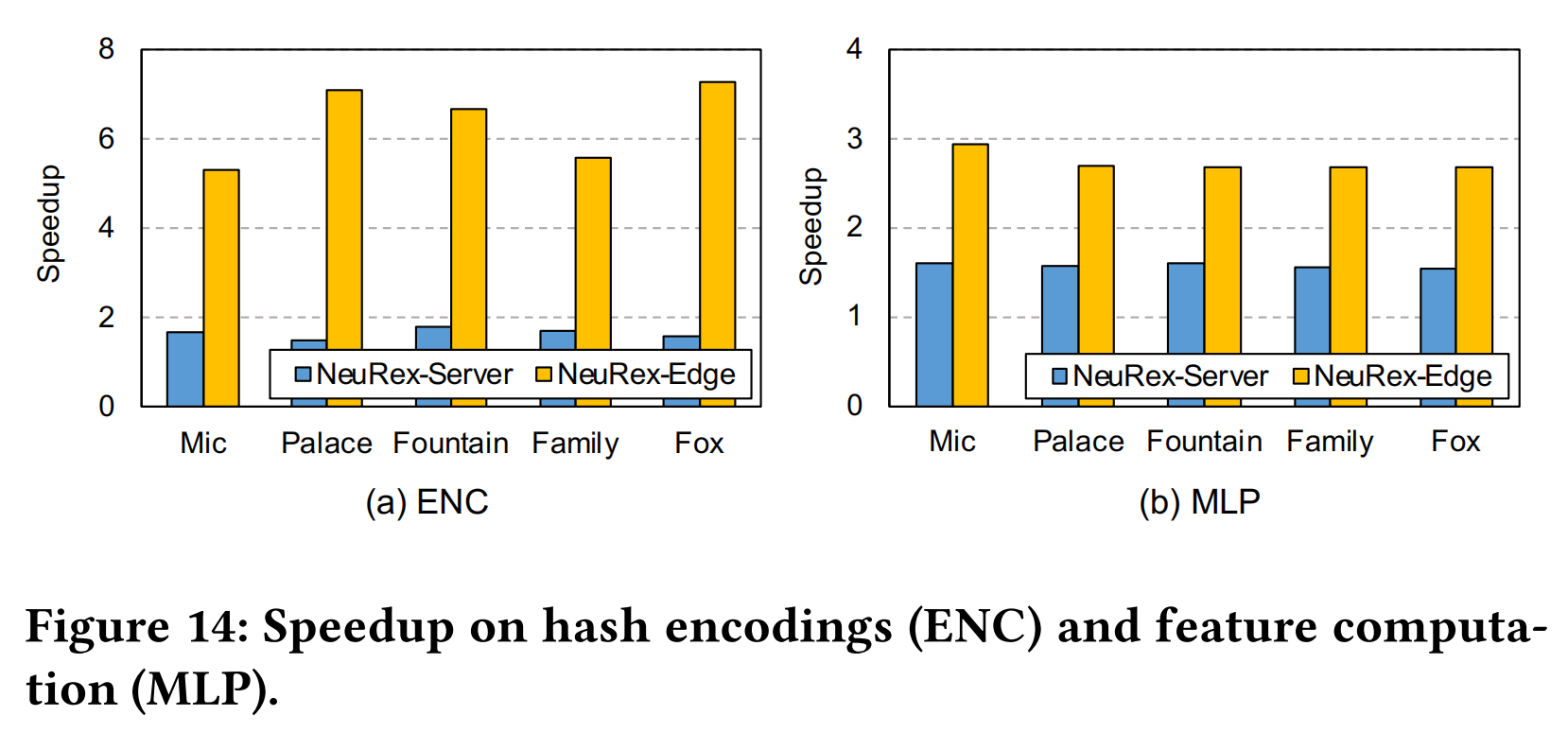
- 与GPU相比,NeuRex的峰值计算吞吐量较低
- 但它执行MLP计算的速度更快
- 全连接层层较小,GPU Tensor Core 的利用率较低,而 NeuRex 中的 TCE 实现了更高的计算利用率
- NeuRex 的整体加速度(图13)高于对 ENC 和 MLP 的单独加速度
- 这两个操作在原始执行流中是串行的,而 NeuRex 通过受限制的哈希使它们可以重叠执行。
Rendering Quality
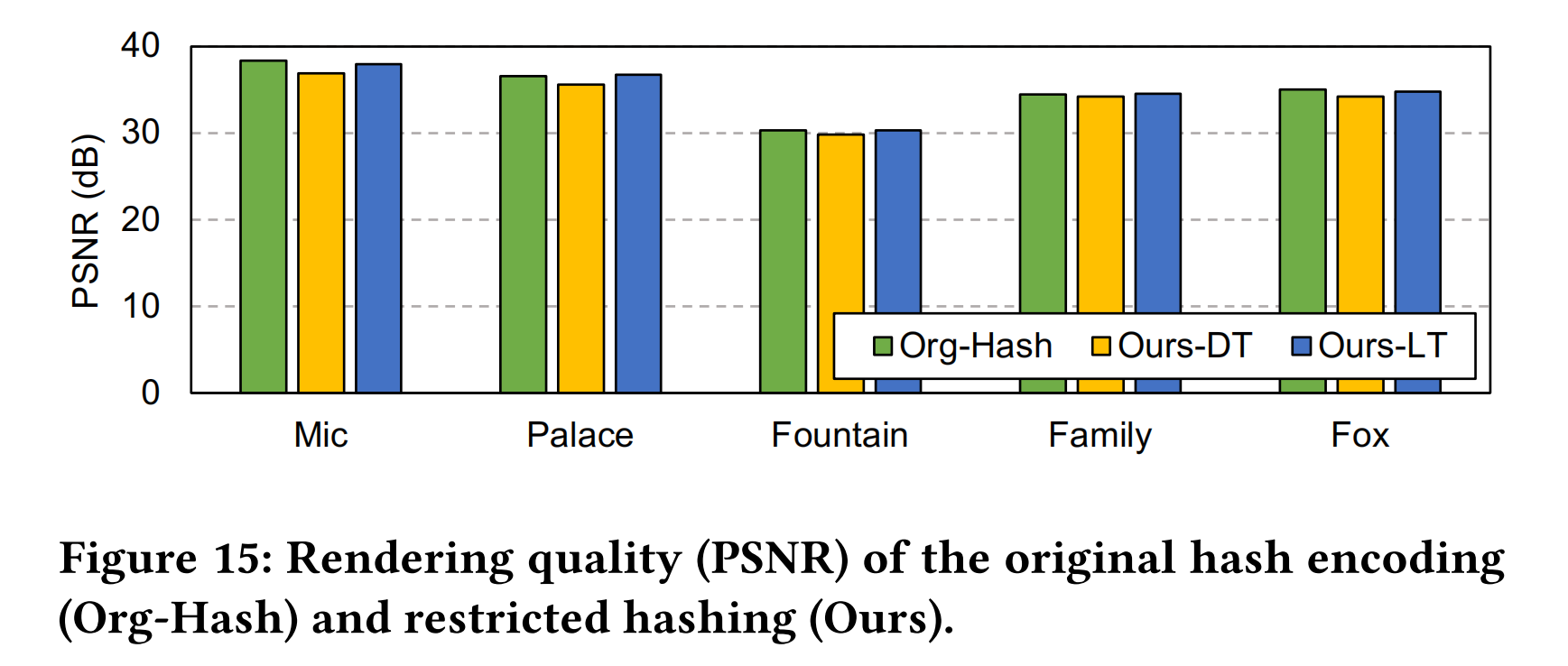
- Restricted Hashing 限制了每个 Batch 只能访问单个 Subgrid Buffer 内的输入编码。
- 增加哈希表大小对性能影响较小,因为每次只需加载部分 Entries 到芯片上。
- 配置了一个 4 倍大的哈希表( Ours-LT ;每个级别 8MB ),以进一步提高 PSNR 而不影响性能
- 结果显示,Ours-LT在最坏情况下仅导致PSNR轻微下降 $1.1%$ ,在其他几个场景中,甚至产生比 Org-Hash 更高的 PSNR 值。

DT: Default Table Size
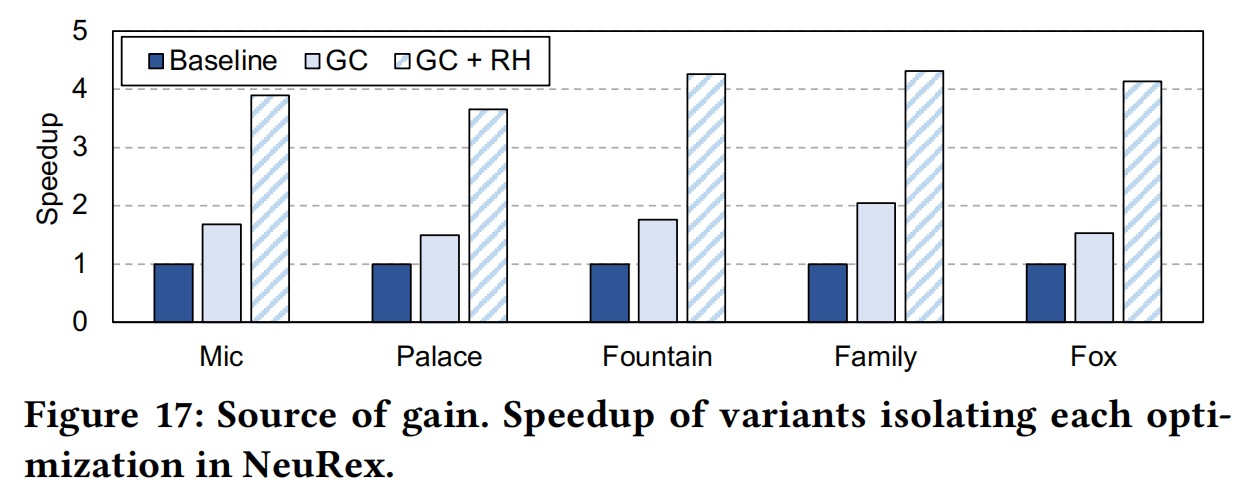
- GC: Grid Cache
- RH: Restricted Hashing

【PaperReading】NeuRex
https://hypoxanthineovo.github.io/2023/06/21/PaperReading/Paper-NeuRex/