【科技文明通论 期末论文】智能的逆流与边界
智能的逆流和边界:AI浪潮下的“为何”与“如何”
摘要:在 2023 年,由 OpenAI 推出的 ChatGPT 带来了人工智能的新时代,成为增长最快的网络平台之一。然而,这并不意味着 AI 已经能够替代人类处理所有事务。它仍然出现了一些不完美的地方:即所谓的“逆流”与“边界”——人工智能虽然可以在一些领域取得远超人类的能力,却仍然在很多看起来并不复杂的事情上具有相当的局限性。本文尝试从技术、经济和社会三个角度分析和解释人工智能出现“逆流”和“边界”的原因,并思考和探索这样一个问题:在这样的时代背景下,我们——科研工作者、智能产业的一员,以及时代里的普通人,应该何去何从?
关键词:人工智能,逆流,边界,科学态度,技术与人
1. 背景介绍
在刚刚过去的 2023 年里,随着 OpenAI 推出的 ChatGPT 一炮而红,成为有史以来增长最快的网络平台之一,AI 大模型这个概念几乎横扫了全球的学术圈和创业-投资圈。学术圈里,和大模型结合的论文占据了机器学习相关会议、期刊的半壁江山;创业-投资圈里,大量打着大模型旗号的创业公司风生水起,推出各色各样相近又不相同的大模型服务。几乎所有学校都有大量实验室在大模型方向开始耕耘,几乎所有的互联网公司都推出了自己的大模型服务。
在人工智能的历史里,除了少数的几个爆发时刻,它都只是在跌宕起伏里沉寂。而无疑,ChatGPT 带来的这个新时代里,是人工智能闪耀的爆发时代。人们又开始重拾自己对所谓“强人工智能【Goertzel, Ben. (2014). Artificial General Intelligence: Concept, State of the Art, and Future Prospects. Journal of Artificial General Intelligence. 10.2478/jagi-2014-0001.】”的渴望,我们都在期待着它能够带我们步入全新的幸福世界里。
但这一切并不是完美的。有人感慨:我们希望机器人帮助人类扫地、洗碗,是因为人类要去写诗、画画。现在机器人都去写诗、画画了,人类却还在扫地、洗碗——
这就是我们要提出的两个概念:“逆流”和“边界”。
“逆流”,是指在某些我们认为需要高级智能和复杂思考的任务上,比如艺术创作或深度学习,人工智能表现出了超出人类的能力。然而,在一些看似简单的任务上,如清洁或洗碗,人工智能却面临挑战。这是因为人工智能并不是通过理解和感受来学习,而是通过对大量数据和其中模式的分析。
另一方面,“边界”揭示了人工智能的局限。人工智能的性能和功能取决于其训练数据和算法,只能在特定的任务和环境中表现出优越性。一旦超出这些预设的范围,“边界”,人工智能的表现就可能大幅度下降。这就解释了为什么人工智能在一些特定的领域中能超越人类,但在全面的、需要广泛理解和适应性的任务上,人工智能仍然无法与人类相匹敌。
本文将主要包含两个部分:
- 首先,我们尝试从技术、经济和社会这几个不同角度分析,“逆流”和“边界”出现的原因是什么;
- 其次,我们思考,在这个新的时代里,我们应该如何去引导技术的发展,去突破这所谓的边界?我们应该如何对待那些我们生活中的新技术?
或许,我们想要的答案并不在于,去简单地直接期待机器人替代我们所做的各种琐事,而在于重新审视人与技术之间的关系。站在逆流之中,我们应当审视自身,思考技术的本质意义,以及如何在这个瞬息万变的科技时代中保持人性的温暖和智慧。或许,只有在人与技术相互融合、共同发展的道路上,我们才能找到答案,迈向一个更加美好、和谐的未来。
2. 逆流与边界:AI 技术为何偏离我们曾经的预期
纵观上世纪以来,在有关于人工智能的幻想里,我们对人工智能【阿瑟·克拉克 著 郝明义 译.2001太空漫游.上海.上海人民出版社.2014-5】的幻想几乎都是,人工智能用强大的生产能力替代了工人、农民和服务业人员,让绝大多数的人无所事事,从而引发一系列的现象或者问题。
但这轮热潮中,我们见到的现象并非如此:人工智能似乎在写作、绘画、智力工作(比如围棋【人工智能取得新突破, 电脑程序首次击败围棋专业选手.新华网.2016-01-28】)和音乐上体现了惊人的,媲美乃至于超过人类的能力,但似乎那些在我们生活中各色各样的琐碎的事务,诸如扫地、洗碗……等等事情,却仍然是由我们人类自己来做。有人调侃道:“我们希望机器人帮助人类扫地、洗碗,是因为人类要去写诗、画画。现在机器人都去写诗、画画了,人类却还在扫地、洗碗。”
这是为什么?
2.1. 技术角度
对于人类来说,扫地洗碗是非常简单的事情,甚至几乎不需要学习;而写作、绘画和音乐则需要大量的学习才能做到。因此,我们认为,前者是“简单”的事情,后者是“困难”的事情。因此,当我们的人工智能能够做到写作、绘画这类我们认为“复杂”的事情时,我们会下意识地认为,那些被我们认为“简单”的事情,一定能被人工智能所轻易掌握。
但是事实并非如此。事实上,这就是当前人工智能浪潮中所存在的两个问题:
- “逆流”:人工智能能处理一些我们觉得非常困难的事务,比如写作、绘画;
- “边界”:人工智能在一些我们觉得并不困难的事物上表现平平。
这是为什么呢?让我们关注两个角度的事实:
1. 对于不同的方法而言,“简单”和复杂不能一概而论
在一些问题上,人类和计算机处理信息的方案有非常明显的区别:
在计算能力上,大部分普通人只能心算两位数左右的乘法,或者三四位数的加法,而计算机执行乘法运算则强大的多。现在的一台计算设备(如:RTX 4060)的算力是15.1 TFLOPS【GeForce RTX 4060 Ti & 4060 显卡, NVIDIA.https://nvidia.cn/geforce/graphics-cards/40-series/rtx-4060-4060ti/】,也就是说,它可以可以在一秒内进行一万亿次准确的32位浮点数乘法运算,这需要一个人类算数百万年;但是在估算能力上,人脑的某些未知的机制可以让人脑在某个时间内对某些非常复杂的问题给出一个非常接近最优解的边界,而计算机使用的大部分算法,即使拥有更强大的算力,也需要非常久的时间。
以旅行商问题为例:假设每个点代表一个城市,一个售货员必须访问所有城市,并且恰好访问每个城市一次,并最终回到出发城市。旅行商问题就是找总路径最短的走法。
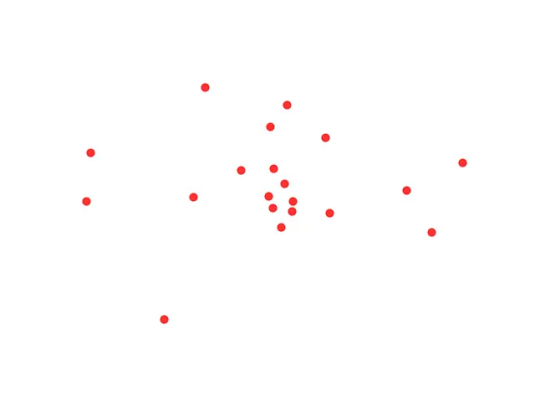
我们随机给出20个点,几乎大部分人都能在相当短的时间内找到一个接近最优解的方案:
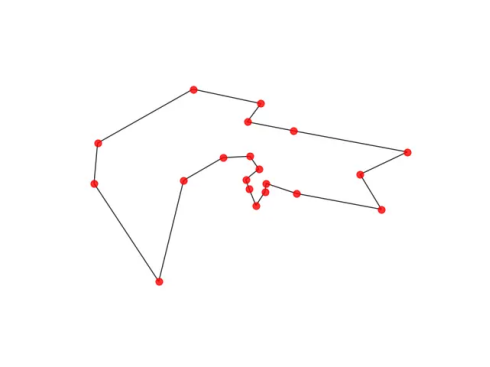
通过计算机模拟,这个路径的总长度是20.45。
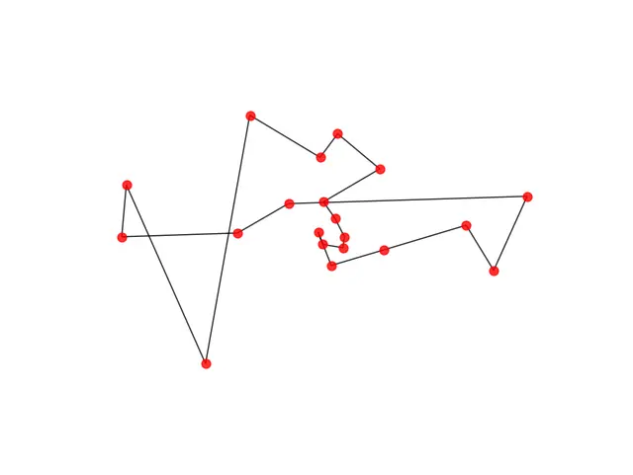
而使用计算机的常见算法(例如:贪心算法)也能给出一个解答,但即使我们不提到这个方案的距离结果,我们也能“感觉”到,它不是一个很好的解答。(事实上,这个解法的距离是24.48)。
事实上,目前对人类到底通过什么样的方案去估算,并没有一个确定的解答。有人认为是人类自动采取了一些经验策略,也有人说人类可以快速排除那些劣等的方案,得到一个比较不错的结果。但无论如何,这种估算能力,是目前开发的各种经验算法所难以完全媲美的。
因此,我们可以认为,在一些问题上,我们所体会到的复杂程度与计算机和其中的人工智能相比,会有很明显的区别。
就以扫地的例子,我们来尝试用逻辑去构建一个程序,来实现相应的功能:
- 首先,我们需要知道什么时候扫地:可能需要判断“场景”是否合适——在宴请宾客的时候显然不适合扫地;在需要安静的时候也不应该扫地;在刚扫完不久又没有意外情况的时候,也不应该扫地……事实上,这个判断就已经是非常主观的问题,想准确划定边界就已经是难中之难。
- 然后,扫把在哪里?对于一个完全自主的机器人来说,它可能需要先去寻找上次存放扫把的位置;但如果不在的话怎么办呢?用什么策略去搜索?是否需要向它的“主人”询问?什么时候询问?……这又涉及到一系列问题。
- 现在,机器人已经拿到了扫把。它该如何去进行扫地工作?如何去防止碰到其他人?在场景可能和上次有所不同的情况下,如何判断哪些地方需要扫,哪些地方(诸如地上的玩具)是不该扫的?怎么规划路线?……这又是一些没有固定解的问题。甚至某些相似的场景里,它可能需要做出不同的决策。(比如:孩子把玩具打坏了,或者只是放在地上)
仅仅是进行一些简单的分析,我们就能意识到,这些日常事务的复杂程度远远超出了我们原本的预期。那为什么我们会觉得它们并不困难呢?
2. 人类经过了非常足够的“预训练”
事实上,我们所经受的预训练比我们所以为的更多:且不谈从出生开始,我们每时每刻都在接受周围的信息【每天接收约34GB信息,大脑要超载. 新华网, 2009 年 12 月 15 日,https://www.chinanews.com.cn/it/it-itxw/news/2009/12-15/2019016.shtml】。无论是看到父母的行为,还是听到其他人之间的对话,都对我们的行为有潜移默化的影响;就单说由基因指导发育而来的大脑,其本身就已经携带了相当多的信息。可以说,大脑在进行“初始化”的时候,就已经是经过一次预训练的状态了。
因此,对于一个在正常社会中健康成长的人来说,上述问题恐怕都未必是问题:
- 什么时候扫地?——需要扫的时候就扫嘛!这本质上是个经验和习惯使然的概率问题;
- 如何找?按照逻辑去寻找!正常人当然不会把扫把放在一些很奇怪的地方,而且也可以通过回忆去推理可能的位置;
- 扫地的路线更不是问题,从某个房间开始扫扫就行了;
- …
我们所经过的大量“预训练”给了我们足够的“经验”,让我们在遇到大多数情况的时候,可以下意识做出一些接近最优解——至少原理劣解的方案,并且很多经验可能具有相当强的泛化性。
这也就解释了为什么很多我们认为简单的事情 AI 难以处理。那,美术、音乐等事情,AI 又是如何解决的呢?
3. 艺术的体验和评价仍然是人类进行的
与此相比,无论是视觉艺术如绘画,还是听觉艺术如音乐,它们都有一个共同的特点:艺术的创造和欣赏都是由人类主导的。
以绘画为例,每一幅画作都是画家内心情感的外化,是他们对世界的理解和感受的记录。画家的每一笔、每一色,都载着他们的喜怒哀乐,他们的思考和追求。而当我们欣赏这些画作时,我们也会在画家的世界中找到共鸣,感受到他们的情感,理解他们的思想。这个欣赏的过程是作者和读者共同完成的。
然而,AI 的创作方式【McIntosh, Timothy & Susnjak, Teo & Tong, Liu & Watters, Paul & Halgamuge, Malka. (2023). From Google Gemini to OpenAI Q* (Q-Star): A Survey of Reshaping the Generative Artificial Intelligence (AI) Research Landscape. 10.48550/arxiv.2312.10868.】截然不同。AI 通过以大量的艺术作品作为输入,去用类似记忆的方式,学习不同的作品描述所对应的概率函数,掌握了一种”模拟”创作的能力。它可以生成样式各异的画作,甚至能模仿出莫奈、毕加索等大师的风格。然而,这些产生的作品并不包含AI的情感或思想,因为 AI 并不能理解这些概念。它只是在模仿和生成,而非真正的创作。
因此,我们似乎感觉 AI 能够创作出很多奇妙的作品,但是,当我们欣赏 AI 生成的艺术作品时,我们其实是在体验自己的情感和思想。我们在这些作品中看到的美和感动,其实是我们自己的内心反映。这就是为什么,尽管AI可以生成出色的艺术作品,但人类仍然是艺术创作和欣赏的主导者。
这就是我们之前所提到的”逆流”现象的体现。通常,我们会认为艺术创作是一项复杂的任务,需要深度的理解和感受,需要丰富的经验和技巧。这种逆流现象揭示了人工智能的一种根本特性:AI的能力并不是按照我们的直觉或经验来分布的。它的能力取决于它的学习和训练,取决于它可以获取和处理的数据。
因此,在技术角度,我们可以总结“逆流”和“边界”的出现的原因:
- 首先,”逆流”现象的出现,主要源于人工智能的学习方式。人工智能并不是通过理解和感受来学习,而是通过分析大量的数据和找出其中的模式。因此,AI在那些可以获取大量数据并且有明确模式的任务上,如艺术创作,表现出了惊人的能力。
- 其次,”边界”现象的出现,主要源于人工智能的局限性。在某些看似简单但实际上需要深度理解和感知的任务上,如清扫或洗碗,AI 却意外地表现出了困难。AI 的能力取决于它的训练数据和算法,因此,它只能在特定的任务和环境中表现出优越性。一旦超出了这些范围,AI 的性能就会大幅下降。这就是为什么 AI 在一些特定的任务上表现出了超越人类的能力,但在整体上,尤其是在需要广泛理解和适应力的任务上,AI 仍然无法与人类相比。
- 但是,人工智能没有深入进入我们生活的原因绝不仅限于技术。如果有足够投入的话,刚才提到的很多问题,都有可能被聪明的人们设法解决。接下来,我将从其他两个角度——经济和社会,来分析人工智能技术的局限性。
2.2. 经济角度
考虑一项技术是否实用,不能仅仅考察其效果,更要考察其成本。如果一项技术只有全球前十万分之一的人能用的起,那恐怕这项技术就很难谈得上“进入我们的生活”。因此,一个技术的实用价值,还要考虑其广泛可用性和可负担性。
一个非常现实的事情是,现在绝大多数 AI 技术的成本【数据猿. 云计算成本大揭秘,2023年6月22日,https://new.qq.com/rain/a/20230622A003YD00】,几乎都远远大于人类:购买一张大型计算设备的计算卡所需的资金,可能相当于一个全职清洁工几年的工资。而大型计算设备需要数以千计的计算卡,并且还伴随着巨大的电力、散热和维护成本,这对普通人来说是无法承受的。
这就引出了一个关键问题:即使我们投入大量人力物力,研发出的最先进的 AI 模型能够处理各种杂务,对于数十亿分之一的我们而言,又有何意义呢?
我们需要意识到,技术的发展并非简单直接的线性行为,而是需要在效果和成本之间找到一个平衡。如果一种技术只关注于提升效果,而忽视了其对使用者的负担,那么这种技术的实用性就大打折扣。
另外,我们还需要考虑到技术的普及程度。一个技术如果只有少数人能用,那么它的影响力就会大大减小,不能真正推动社会进步。因此,我们在研发新技术的时候,不仅要考虑到其科技水平,也要考虑到其普及性和可持续性。
总的来说,一个真正有意义的技术,应该是既可以提升效果,又可以被大多数人所接受和使用的。这样的技术,才能真正改变我们的生活,推动我们的社会向前发展。当下,AI 技术的成本问题,限制了它的广泛应用。对于大多数人来说,高昂的设备成本和运营成本使得他们难以接触和使用这些先进的技术。这导致 AI 技术的普及程度低,无法在更广泛的领域发挥其潜在价值。
2.3. 社会角度
如今的 AI 浪潮下,我们面临着一个至关重要的挑战,那就是在众多关键的社会事务中,人工智能往往无法承担起应由人类承担的责任。这不仅涉及到技术的局限性,更触及到我们对于责任、道德和社会公正的理解。在此背景下,我们需要深入探讨AI的边界,理解其在处理复杂社会问题时的逆流,从而寻找到一种能够平衡技术进步和社会责任的方法。我们以两个不同领域的例子来分析问题:
2.3.1. 智能驾驶中的社会责任问题
智能驾驶是人工智能在现实生活中的重要应用之一。然而,当发生意外情况时,人工智能的处理能力就显得相对薄弱。例如,在一次由于天气原因导致的交通事故中,虽然自动驾驶车辆已经尽可能执行了预设的避险程序,但由于无法像人类驾驶员那样对状况进行深度理解和即时判断,最终还是未能避免事故的发生。
在这种情况下,我们面临的主要问题就是如何确定人工智能的责任归属【刘凯,自动驾驶车祸谁担责?AGI专家详解法律责任,突破伦理困境:渤海大学教育科学学院、渤海大学通用人工智能研究所,2021. https://mp.weixin.qq.com/s/ZRauhiypIKqJxf9uDetS3A】。人工智能本质上是一种由复杂算法和程序构成的系统,它按照预设的规则和参数进行操作,但并无法理解或承担道德和责任的含义。这就使得责任归属问题变得极具挑战,既涉及到技术层面的讨论,也引发了法律和道德层面的深度思考。
此外,人工智能的可解释性问题也令人担忧。对于人类驾驶员来说,他们可以通过保持良好的休息、避免在恶劣天气中驾驶等方式来降低出错的可能性。然而,人工智能的错误往往源于模型的不可预测性和不可解释性,这使得错误发生的可能性变得难以预料。人们通常会更难接受这种无法预防和理解的错误。这些问题都凸显了,尽管人工智能在智能驾驶等领域具有巨大的潜力,但在实际应用中,我们仍然需要面对其存在的局限性和挑战。
2.3.2. 经济、法律等领域中的责任问题
现在网络上有一个笑话:人工智能永远不能代替会计和律师,因为它不能坐牢。事实也确实如此:
在经济领域,AI已经广泛应用于金融市场预测、投资决策等方面。然而,当某一投资决策失败,导致经济损失时,我们不能简单地将责任归咎于AI。因为,AI只是根据预先输入的数据和算法进行决策,它并无法理解和承担责任的含义。
类似地,在法律领域,AI 可以帮助我们分析大量的法律文本、案例和先例,但当需要进行法律判断、道德考量以及责任归属确定等复杂任务时,AI 的局限性就会显现出来。因为这些任务不仅需要理性的逻辑分析,更需要深度的情感理解、道德判断以及对法律精神的深入把握,这是目前的 AI 技术无法实现的。
在这个过程中,我们需要对 AI 的应用有更深入的理解和更审慎的态度。AI 是一种强大的工具,它可以帮助我们处理大量的数据和复杂的问题,但它并不能替代人类进行深度的思考和责任的承担。我们应该适当地使用 AI ,而不是过度依赖它,更不能期待它来承担应由人类承担的责任。
总结,人工智能在处理复杂社会事务上的局限性揭示了我们需要在技术进步与社会责任之间找到平衡,这需要我们整合多领域的知识,包括计算机科学、经济、法律、伦理学等,以构建一个全面、合理的 AI 责任框架。这样,我们才能保证 AI 的持续发展,同时确保社会的公平、公正和稳定。
3. 界中人:浪潮下,我们如何自处
在前文中,我们总结了一些人工智能的现状,我们称之为“逆流”和“边界”——一方面,由于技术路线的原因,人工智能能够解决某些我们认为很复杂的问题;另一方面,它却在我们觉得简单的事情上遇到很大的困难乃至于束手无策。在这种矛盾而又不可思议的现状下,我们需要思考一个问题:面对这股涌动的浪潮,我们应该如何定位自己,如何在其中找到自己的立足之处?
3.1. 求知:对于理论上的可解释性的持续追求
对于从事人工智能理论研究的科学家们,可解释性成为了他们的首要追求。在大部分情况下,我们并不能满足于一个庞大且神秘的”黑箱”,即使它的表现超越了所有人类。我们渴望理解其内在工作原理,掌握其背后的逻辑和规则,这是我们对知识的尊重,也是对科学的敬畏。
作为一名专注于计算机科学研究的学者,我认为追求人工智能的可解释性可以从以下两个方向深入开展:
- 基于高维数学物理方法的深度学习解释:深度学习模型的内部机制复杂且高维,要理解其工作原理,我们需要借助于高维数学和物理学的理论。这可能包括研究高维空间的几何性质,理解深度学习模型如何将输入数据映射到这个高维空间,以及如何在这个空间中寻找最优解【Na Lei, Dongsheng An, Yang Guo, Kehua Su, Shixia Liu, Zhongxuan Luo, Shing-Tung Yau, Xianfeng Gu.A Geometric Understanding of Deep Learning[J].Engineering,2020,6(3):361-374.】。这一方向的研究可以帮助我们揭示深度学习模型的内部运作逻辑,理解其如何处理和理解数据,以及为何能够取得如此出色的效果。
- 结合传统数理方法的新智能框架:另一方向是尝试将传统的数理方法与现代的人工智能技术结合,构建新的智能框架。这可能包括将统计学习理论、图论、最优化理论等传统数理方法引入到人工智能模型中【Ren, Qihan & Gao, Jiayang & Shen, Wen & Zhang, Quanshi. (2023). Where We Have Arrived in Proving the Emergence of Sparse Symbolic Concepts in AI Models.】,以提高模型的可解释性和鲁棒性。这一方向的研究可以帮助我们构建出既有强大性能,又具有良好可解释性的新型人工智能模型。
热潮过后,我们需要深入探索,去理解ChatGPT等复杂模型背后的原理和逻辑。这是科学家们的责任,也是我们理解和把握新时代关键的途径。只有真正理解了这些技术,我们才能充分利用它们,才能在人工智能的浪潮中找到自己的位置。而这一切,都离不开我们对知识的深度追求,对理论上的可解释性的持续探索。
3.2. 拓荒:在技术上,拓展人工智能与生活的边界
除了深入探索学术理论,我们也需要考虑人工智能技术如何更好地融入我们的日常生活。这是一个至关重要的议题,因为如果人工智能只能为少数拥有高端计算设备的富裕人群提供服务,那么它的影响力将非常有限。
在追求技术进步和提升智能能力的同时,我们必须关注如何更好地将这些技术应用到我们的日常生活中。无论是与传统产业的融合,如小米的智能工厂,这种将人工智能技术应用在生产线上,提升效率,降低人工成本;还是与传统科学的结合,如 AI For Science 项目,通过利用人工智能技术解决科学问题,推动科学发展,都是值得我们深入探索的方向。
另一方面,我们也需要鼓励和推崇开发低功耗的智能系统。任何技术,无论其效果有多么出色,如果其能耗过高,那它就很难真正融入我们的日常生活。除非我们突然找到了实用的可控核聚变技术,否则我们必须一直关注能源效率问题。例如,我们的智能手机就是一种低功耗的设备。尽管它们的计算能力远不及大型数据中心,但是它们仍然能够运行各种复杂的人工智能应用,如语音识别、图像识别等。另外,像一些智能家居设备,比如智能恒温器、智能灯泡等,也是在低能耗的前提下,实现了智能化。
因此,我们在拓展人工智能技术的边界时,不仅要注重提升其智能水平,也要考虑其能耗问题,只有这样我们才能真正将人工智能带入每个人的生活中。
3.3. 拥抱:于我们自身,永远不对新技术设限
抛开学术界的身份,作为时代中的一粒尘埃般的人,我们该如何自处?或许我们能做的,也只有永远不设限这一件事情了。
面对 GPT 的时候,先不去反驳“这种东西肯定不靠谱”;面对 AI 绘画的时候,不要一开始就否定其作品的艺术价值,而是先尝试理解和欣赏;面对那些 AI 换脸、拟声技术的时候,认真对待,和朋友约定一些暗号防止被这些技术欺骗,而不是大大咧咧的说“我怎么可能会上当”……这些细节体现的是我们对技术的尊重,是一种不预设任何结论,而是去亲身实践的科学态度。
无论我们是青年、中年还是老年,无论我们是普通百姓、白领工作人员还是达官显贵,只有我们怀揣着科学的态度,尊重新技术,才能在这个飞速变化的时代里找到方向,掌握未来的机会。在过去的百多年里,我们经历了无数的废弃和创新,无数的旧事物消失,无数的新事物诞生。在那十八弯的时代洪流里,唯有科学的思考是不变的灯塔。
总结
本文旨在探讨,人工智能(AI)的发展现状及其对社会的影响。AI技术在许多领域,如艺术创作和深度学习,已经显示出超越人类的能力,这被称为“逆流”。然而,AI在一些看上去简单的任务上却遇到挑战,比如扫地和洗碗,这被称为“边界”。这种现象揭示了AI的局限性:它的能力取决于其训练数据和算法,只能在特定的任务和环境中表现出优越性。然而,一旦超出这些预设的范围,AI的表现就可能大幅度下降。
本文从技术、经济和社会三个角度分析了AI的“逆流”和“边界”现象。在技术角度,我们需要了解和掌握AI的工作原理,这需要进行深入的理论研究和实践探索。在经济角度,我们必须考虑AI技术的成本问题,以及技术的普及程度。在社会角度,我们需要面对AI在处理复杂社会事务上的局限性,包括确定AI的责任归属,以及处理AI的可解释性问题。
在面对AI的发展浪潮时,我们应该怀揣科学态度,尊重新技术,并永远不对新技术设限。我们应该适当地使用AI,而不是过度依赖它,更不能期待它来承担应由人类承担的责任。只有在人与技术相互融合、共同发展的道路上,我们才能找到答案,迈向一个更加美好、和谐的未来。