【PaperReading】RTNeRF & Instant3D
Before
Gatech 组的主要算法优化策略:
- 首先,选择当前的 SOTA 算法
- 对 SOTA 算法进行 Profiling,找到性能瓶颈
- 以增量式优化为主
RT-NeRF
Motivation
认为:目前 NeRF 效率低有两个主要原因:
- The commonly used uniform point sampling method
- 朴素的采样方法)
- The required dense accesses and computations for embeddings
- 密集的 Embedding 访问和计算

先验信息: Sparsities of pre-existing points
最终有效的采样点应该具有稀疏性
优化方法
- Directly computing the geometry of pre-existing points based on the corresponding non-zero cubes of the occupancy grid
- 通过预计算已经存在于 Occupancy Grid 的几何元素,减少采样点数量
- Leverages a coarse-grained view-dependent rendering ordering scheme to avoid processing invisible points
- 通过一个粗粒度的排序,减少对某些不可见点的运算
- Object Ordered 思想
Profiling
对 TensoRF 的 Rendering Pipeline 进行 Profiling。

Profiling


Locate the pre-existing points
All the candidate points are uniformly sampled along rays and then the existence of pre-existing points are identified via a query process based on the occupancy grid.
首先在光线上进行一次预采样,通过 Occupancy Grid 来查询点的存在与否
两个 Inefficiency:
- The sparsity of the occupancy grid is not leveraged
- 没有利用 Occupancy Grid 的稀疏性先验
- The DRAM accesses to the occupancy grid are irregular because the emitted rays can come from any direction, and thus the order of their accesses to the occupancy grid can not be predicted in advance.
- 由于 Ray 的方向并不能预知,Occupancy 的 DRAM-Access 很随机,Locality 差
Proposed Solution?
Directly computes the coordinates of pre-existing points by looping over the non-zero cubes of the occupancy grid.
- 按照 固定的顺序 访问 Occupancy Grid(也即所谓的“Cube”)
Efficient Rendering Pipeline

- 将 Occupancy Grid 中的每个 Non-zero cube 近似为一个球,以方便后续步骤的计算;
- 将上述的球投射到要渲染的图像上,成为一个椭圆(Oval);
- 根据待渲染的图像中的 regular arrangement of points ,即一个点对应一个像素,确定椭圆内的点;
- 使用 Line-Sphere intersections 的解析解来计算出沿着光线射线并且在球内的点的 Geometries。
只有 Pre-exist points 会被包含在循环中。解决了:
- Occupancy Grid 的 Sparsity 没有被充分利用
- 在 SOTA Rendering Pipeline 中, DRAM Access 的不规则性
Early Termination: Volume Rendering
在图形学中,Volume Rendering Integral 的离散化计算主要有两种:
- Front-to-back composition: 从前向后积分
- $\begin{cases}\hat{C_i}=\hat{C}{i+1} + \hat{T{i+1}}C_i\\hat{T_i}=\hat{T}_{i+1}(1-\alpha_i)\end{cases}$
- Back-to-front composition: 从后向前积分
- $\begin{cases}\hat{C_i}=\hat{C_{i-1}}(1-\alpha_i)\\hat{T}i=\hat{T}{i-1}(1-\alpha_i)\end{cases}$
View-Dependent Rendering Ordering
主要 Motivation 来自于:
- Early Termination 要求我们在进行点采样的时候按照 Ray Marching 的顺序进行(从前向后)
- 如果先访问了暂时还没有 Marching 到的点,那这个数值显然不能拿来计算,相当于是一次无效访问
- 如果能让渲染的计算本身变得有序,就能获得更好的 Locality!

- 将 Occupancy Grid 分割成八个 Subspace
- 先计算最接近 View Origin(光线的原点)的子空间将会先进入计算
- 接下来,途中标注
2的部分再进入计算,再接下来是剩下的
效果

Instant 3D
回顾一下Gatech 组的主要算法优化策略:
- 首先,选择当前的 SOTA 算法
- 对 SOTA 算法进行 Profiling,找到性能瓶颈
- 以增量式优化为主
选择当前的 SOTA 算法
—— Instant NGP
对 SOTA 算法进行 Profiling
认为 NGP 的主要瓶颈是对 3D Feature 进行三线性插值
Different paces of Color and Density During Training
重建质量对于 Color 和 Density特征 具有不同的敏感性
- 因为 NeRF 本身重建的 Loss 是 RGB-Based,并没有引入几何形状的约束,几何形状的重建本身是“赠品”
- 因此,Color 部分并不需要和 Density 部分相同的精度(Color 部分粗糙一些也不影响重建效果)
两个优化:
- 两个网格的尺寸不需要一样
- 两个网格的更新频率不需要一样
网格尺寸
遍历了一下两个网格尺寸的比例,找了一些有代表性的结果:
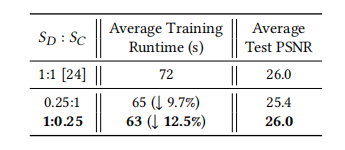
Color Grid 可以使用更小的大小
更新频率
遍历了一下两个网格更新频率的比例,找了一些有代表性的结果: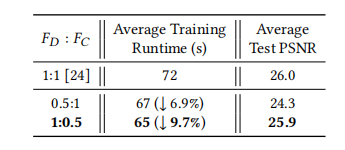
Density Grid 可以使用更小的更新频率
效果
We can trim down the runtime by $83.0%$ as compared to the most efficient NeRF training algorithm [24] on the same edge GPU Xavier NX.